Data Discover and Transformation¶
in this section of the lab, we’ll use Glue to discover new transportation data. From there, we’ll use Athena to query and start looking into the dataset to understand the data we are dealing with.
We’ve also setup a set of ETLs using Glue to create the fields into a canonical form, since all the fields call names different things.
After understanding the data, and cleaning it a little, we’ll go into another notebook to perform feature engineering and time series modeling.
What are Databases and Tables in Glue:¶
When you define a table in the AWS Glue Data Catalog, you add it to a database. A database is used to organize tables in AWS Glue. You can organize your tables using a crawler or using the AWS Glue console. A table can be in only one database at a time.
Your database can contain tables that define data from many different data stores.
A table in the AWS Glue Data Catalog is the metadata definition that represents the data in a data store. You create tables when you run a crawler, or you can create a table manually in the AWS Glue console. The Tables list in the AWS Glue console displays values of your table’s metadata. You use table definitions to specify sources and targets when you create ETL (extract, transform, and load) jobs.
import boto3
database_name = '2019reinventWorkshop'
## lets first create a namespace for the tables:
glue_client = boto3.client('glue')
create_database_resp = glue_client.create_database(
DatabaseInput={
'Name': database_name,
'Description': 'This database will contain the tables discovered through both crawling and the ETL processes'
}
)
This will create a new database, or namespace, that can hold the collection of tables
https://console.aws.amazon.com/glue/home?region=us-east-1#catalog:tab=databases

create db response
You can use a crawler to populate the AWS Glue Data Catalog with tables. This is the primary method used by most AWS Glue users. A crawler can crawl multiple data stores in a single run. Upon completion, the crawler creates or updates one or more tables in your Data Catalog. Extract, transform, and load (ETL) jobs that you define in AWS Glue use these Data Catalog tables as sources and targets. The ETL job reads from and writes to the data stores that are specified in the source and target Data Catalog tables.
crawler_name = '2019reinventworkshopcrawler'
create_crawler_resp = glue_client.create_crawler(
Name=crawler_name,
Role='GlueRole',
DatabaseName=database_name,
Description='Crawler to discover the base tables for the workshop',
Targets={
'S3Targets': [
{
'Path': 's3://serverless-analytics/reinvent-2019/taxi_data/',
},
]
}
)
response = glue_client.start_crawler(
Name=crawler_name
)
After starting the crawler, you can go to the glue console if you’d like to see it running.
https://console.aws.amazon.com/glue/home?region=us-east-1#catalog:tab=crawlers

After it finishes crawling, you can see the datasets (represeted as
“tables”) it automatically discovered. 
Waiting for the Crawler to finish¶
import time
response = glue_client.get_crawler(
Name=crawler_name
)
while (response['Crawler']['State'] == 'RUNNING') | (response['Crawler']['State'] == 'STOPPING'):
print(response['Crawler']['State'])
# Wait for 40 seconds
time.sleep(40)
response = glue_client.get_crawler(
Name=crawler_name
)
print('finished running', response['Crawler']['State'])
RUNNING
RUNNING
STOPPING
STOPPING
finished running READY
Querying the data¶
We’ll use Athena to query the data. Athena allows us to perform SQL queries against datasets on S3, without having to transform them, load them into a traditional sql datastore, and allows rapid ad-hoc investigation.
Later we’ll use Spark to do ETL and feature engineering.
!pip install --upgrade pip > /dev/null
!pip install PyAthena > /dev/null
Athena uses S3 to store results to allow different types of clients to read it and so you can go back and see the results of previous queries. We can set that up next:
import sagemaker
sagemaker_session = sagemaker.Session()
athena_data_bucket = sagemaker_session.default_bucket()
Next we’ll create an Athena connection we can use, much like a standard JDBC/ODBC connection
from pyathena import connect
import pandas as pd
sagemaker_session = sagemaker.Session()
conn = connect(s3_staging_dir="s3://" + athena_data_bucket,
region_name=sagemaker_session.boto_region_name)
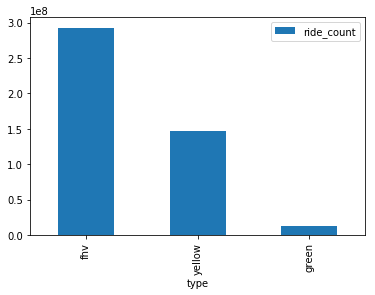
df = pd.read_sql('SELECT \'yellow\' type, count(*) ride_count FROM "' + database_name + '"."yellow" ' +
'UNION ALL SELECT \'green\' type, count(*) ride_count FROM "' + database_name + '"."green"' +
'UNION ALL SELECT \'fhv\' type, count(*) ride_count FROM "' + database_name + '"."fhv"', conn)
print(df)
df.plot.bar(x='type', y='ride_count')
type ride_count
0 green 12105351
1 yellow 147263398
2 fhv 292722358
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c9ad19828>
green_etl = '2019reinvent_green'
response = glue_client.start_job_run(
JobName=green_etl,
WorkerType='Standard', # other options include: 'G.1X'|'G.2X',
NumberOfWorkers=5
)
print('response from starting green')
print(response)
response from starting green
{'JobRunId': 'jr_d51a70e617a0c7459b3af986ff047ee211696c13ce509736ba01f4778b45b759', 'ResponseMetadata': {'RequestId': '40ef03ea-1387-11ea-a9c8-7df52ce46fb6', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Sat, 30 Nov 2019 15:37:02 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '82', 'connection': 'keep-alive', 'x-amzn-requestid': '40ef03ea-1387-11ea-a9c8-7df52ce46fb6'}, 'RetryAttempts': 0}}
After kicking it off, you can see it running in the console too: https://console.aws.amazon.com/glue/home?region=us-east-1#etl:tab=jobs
WAIT UNTIL THE ETL JOB FINISHES BEFORE CONTINUING! ALSO, YOU MUST CHANGE THE BUCKET PATH IN THIS CELL - FIND THE BUCKET IN S3 THAT CONTAINS ‘2019reinventetlbucket’ in the name
#let's list the s3 bucket name:
!aws s3 ls | grep '2019reinventetlbucket' | head -1
2019-11-30 14:38:27 reinvent-2019reinventetlbucket-656uo7rzqlvu
# syntax should be s3://...
normalized_bucket = 's3://reinvent-2019reinventetlbucket-656uo7rzqlvu'
assert(normalized_bucket != 's3://FILL_IN_BUCKET_NAME')
create_crawler_resp = glue_client.create_crawler(
Name=crawler_name + '_normalized',
Role='GlueRole',
DatabaseName=database_name,
Description='Crawler to discover the base tables for the workshop',
Targets={
'S3Targets': [
{
'Path': normalized_bucket + "/canonical/",
},
]
}
)
response = glue_client.start_crawler(
Name=crawler_name + '_normalized'
)
Let’s wait for the next crawler to finish, this will discover the normalized dataset.¶
import time
response = glue_client.get_crawler(
Name=crawler_name + '_normalized'
)
while (response['Crawler']['State'] == 'RUNNING') | (response['Crawler']['State'] == 'STOPPING'):
print(response['Crawler']['State'])
# Wait for 40 seconds
time.sleep(40)
response = glue_client.get_crawler(
Name=crawler_name + '_normalized'
)
print('finished running', response['Crawler']['State'])
RUNNING
RUNNING
STOPPING
STOPPING
finished running READY
Querying the Normalized Data¶
Now let’s look at the total counts for the aggregated information
normalized_df = pd.read_sql('SELECT type, count(*) ride_count FROM "' + database_name + '"."canonical" group by type', conn)
print(normalized_df)
normalized_df.plot.bar(x='type', y='ride_count')
#
type ride_count
0 fhv 292722358
1 yellow 147263386
2 green 12105351
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c8f4570f0>
query = "select type, date_trunc('day', pickup_datetime) date, count(*) cnt from \"" + database_name + "\".canonical where pickup_datetime < timestamp '2099-12-31' group by type, date_trunc(\'day\', pickup_datetime) "
typeperday_df = pd.read_sql(query, conn)
typeperday_df.plot(x='date', y='cnt')
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c8f2fc1d0>
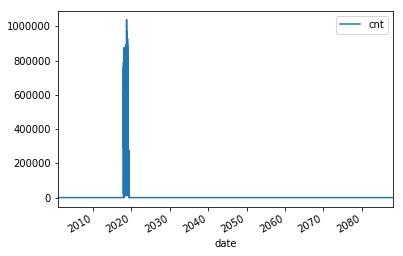
We see some bad data here…¶
We are expecting only 2018 and 2019 datasets here, but can see there are records far into the future and in the past. This represents bad data that we want to eliminate before we build our model.
# Only reason we put this conditional here is so you can execute the cell multiple times
# if you don't check, it won't find the 'date' column again and makes interacting w/ the notebook more seemless
if type(typeperday_df.index) != pd.core.indexes.datetimes.DatetimeIndex:
print('setting index to date')
typeperday_df = typeperday_df.set_index('date', drop=True)
typeperday_df.head()
setting index to date
| type | cnt | |
|---|---|---|
| date | ||
| 2018-05-01 | yellow | 305434 |
| 2018-05-01 | fhv | 629360 |
| 2018-03-04 | fhv | 716458 |
| 2018-08-11 | fhv | 807873 |
| 2018-04-24 | fhv | 639764 |
typeperday_df.loc['2018-01-01':'2019-12-31'].plot(y='cnt')
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c8f2c6198>
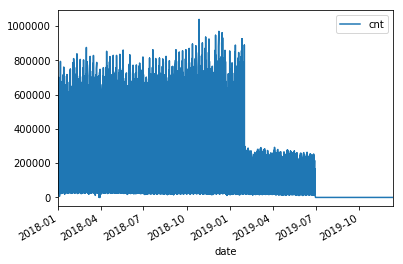
Let’s look at some of the bad data now:
All the bad data, at least the bad data in the future, is coming from the yellow taxi license type.
Note, we are querying the transformed data.¶
We should check the raw dataset to see if it’s also bad or something happened in the ETL process
Let’s find the two 2088 records to make sure they are in the source data
pd.read_sql("select * from \"" + database_name + "\".yellow where tpep_pickup_datetime like '2088%'", conn)
| vendorid | tpep_pickup_datetime | tpep_dropoff_datetime | passenger_count | trip_distance | ratecodeid | store_and_fwd_flag | pulocationid | dolocationid | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | congestion_surcharge | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2088-01-24 00:15:42 | 2088-01-24 00:19:46 | 1 | 0.63 | 1 | N | 41 | 166 | 2 | 4.5 | 0.0 | 0.5 | 0.0 | 0.0 | 0.3 | 5.3 | None |
| 1 | 2 | 2088-01-24 00:25:39 | 2088-01-24 07:28:25 | 1 | 4.05 | 1 | N | 24 | 162 | 2 | 14.5 | 0.0 | 0.5 | 0.0 | 0.0 | 0.3 | 15.3 | None |
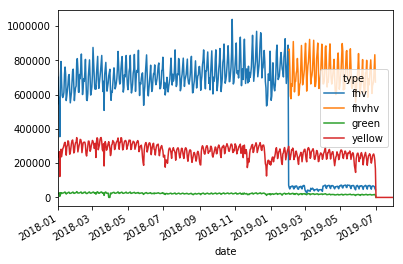
## Next let's plot this per type:
typeperday_df.loc['2018-01-01':'2019-07-30'].pivot_table(index='date',
columns='type',
values='cnt',
aggfunc='sum').plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c8f111a58>
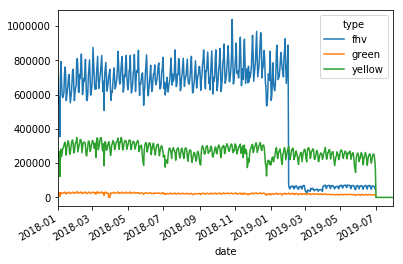
Fixing our Time Series data¶
Some details of what caused this drop: #### On August 14, 2018, Mayor de Blasio signed Local Law 149 of 2018, creating a new license category for TLC-licensed FHV businesses that currently dispatch or plan to dispatch more than 10,000 FHV trips in New York City per day under a single brand, trade, or operating name, referred to as High-Volume For-Hire Services (HVFHS). This law went into effect on Feb 1, 2019
Let’s bring the other license type and see how it affects the time series charts:
create_crawler_resp = glue_client.create_crawler(
Name=crawler_name + '_fhvhv',
Role='GlueRole',
DatabaseName=database_name,
Description='Crawler to discover the base tables for the workshop',
Targets={
'S3Targets': [
{
'Path': 's3://serverless-analytics/reinvent-2019_moredata/taxi_data/fhvhv/',
},
]
}
)
response = glue_client.start_crawler(
Name=crawler_name + '_fhvhv'
)
Wait to discover the fhvhv dataset…¶
import time
response = glue_client.get_crawler(
Name=crawler_name + '_fhvhv'
)
while (response['Crawler']['State'] == 'RUNNING') | (response['Crawler']['State'] == 'STOPPING'):
print(response['Crawler']['State'])
# Wait for 40 seconds
time.sleep(40)
response = glue_client.get_crawler(
Name=crawler_name + '_fhvhv'
)
print('finished running', response['Crawler']['State'])
RUNNING
RUNNING
STOPPING
STOPPING
finished running READY
query = 'select \'fhvhv\' as type, date_trunc(\'day\', cast(pickup_datetime as timestamp)) date, count(*) cnt from "' + database_name + '"."fhvhv" group by date_trunc(\'day\', cast(pickup_datetime as timestamp)) '
typeperday_fhvhv_df = pd.read_sql(query, conn)
typeperday_fhvhv_df = typeperday_fhvhv_df.set_index('date', drop=True)
print(typeperday_fhvhv_df.head())
typeperday_fhvhv_df.plot(y='cnt')
type cnt
date
2019-05-30 fhvhv 723800
2019-04-23 fhvhv 600870
2019-05-23 fhvhv 698940
2019-03-31 fhvhv 794717
2019-03-17 fhvhv 779620
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c8f1cb320>
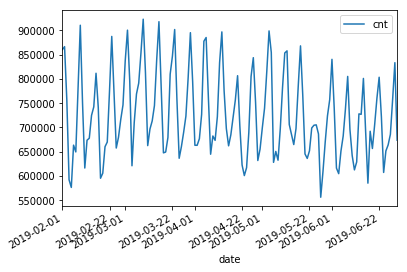
pd.concat([typeperday_fhvhv_df, typeperday_df], sort=False).loc['2018-01-01':'2019-07-30'].pivot_table(index='date',
columns='type',
values='cnt',
aggfunc='sum').plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c8f3a9be0>